Multilingual Semantic Retrieval with
Interleaved Multi-Condition Query

Illustrative examples of multi-condition semantic retrieval
( ). We introduce the
). We introduce the
first interleaved multi-condition semantic retrieval task and benchmark.
Introduction
Semantic retrieval is crucial for modern applications yet remains underexplored in current research. Existing datasets are limited to single languages, single images, or singular retrieval conditions, often failing to fully exploit the expressive capacity of visual information, as evidenced by maintained performance when images are replaced with captions.
However, practical retrieval scenarios frequently involve interleaved multi-condition queries with multiple images. Hence, this paper introduces
, the first multilingual dataset for interleaved multi-condition semantic retrieval, comprising 320,000 queries with 135,000 products in 5 languages, covering 7 distinct product categories.
Extensive experiments on
identify existing models' critical limitation: focusing solely on global semantic information while neglecting specific conditional elements in queries. Consequently, we propose  Coral
, a novel fine-tuning framework that adapts pre-trained MLLMs by integrating embedding reconstruction to preserve fine-grained conditional elements and contrastive learning to extract comprehensive global semantics.
Coral
, a novel fine-tuning framework that adapts pre-trained MLLMs by integrating embedding reconstruction to preserve fine-grained conditional elements and contrastive learning to extract comprehensive global semantics.
Experiments demonstrate that Coral
achieves a 45.9% performance improvement over conventional approaches on
, with strong generalization capabilities validated across 8 established retrieval benchmarks. Collectively, our contributions -- a novel dataset, identification of critical limitations in existing approaches, and an innovative fine-tuning framework -- establish a foundation for future research in interleaved multi-condition semantic retrieval.
MERIT Dataset
Comparison with Previous work
Semantic retrieval is a pivotal task that involves sourcing relevant information from vast data collections to meet specific user requirements. This task has become increasingly important with the advent of AI, as it not only enables precise user recall but also mitigates the risk of inaccuracies in the generated content of Multimodal Large Language Models (MLLM).
However, semantic retrieval remains confined to narrow research scopes, which are limited to single languages, single images, or employing only singular retrieval conditions. Furthermore, many existing works fail to fully exploit the expressive capacity of images, as evidenced by their maintained performance when images are replaced with corresponding captions.
Moreover, in practical applications, product retrieval tasks frequently involve interleaved multi-condition queries (e.g., specific patterns and particular texture), with many aspects requiring visual representation through images.

Comparisons among existing datasets. Left: Previous works are limited to single-condition, single image, single-language scenarios.
Right: Our benchmark enables multilingual semantic retrieval, featuring composite multi-condition queries.
Semantic Retrieval is not only a crucial application in real-world scenarios, such as product search and webpage retrieval, but also facilitates content generation (retrieval-augmented generation) and training for reasoning tasks.
However, existing semantic retrieval datasets are limited to single languages, single images, or singular retrieval condition, often failing to fully exploit the expressive capacity of visual information as evidenced by maintained performance when images are replaced with captions.
is the first multilingual dataset for interleaved multi-condition semantic retrieval. Comparison of related works can be seen in below.
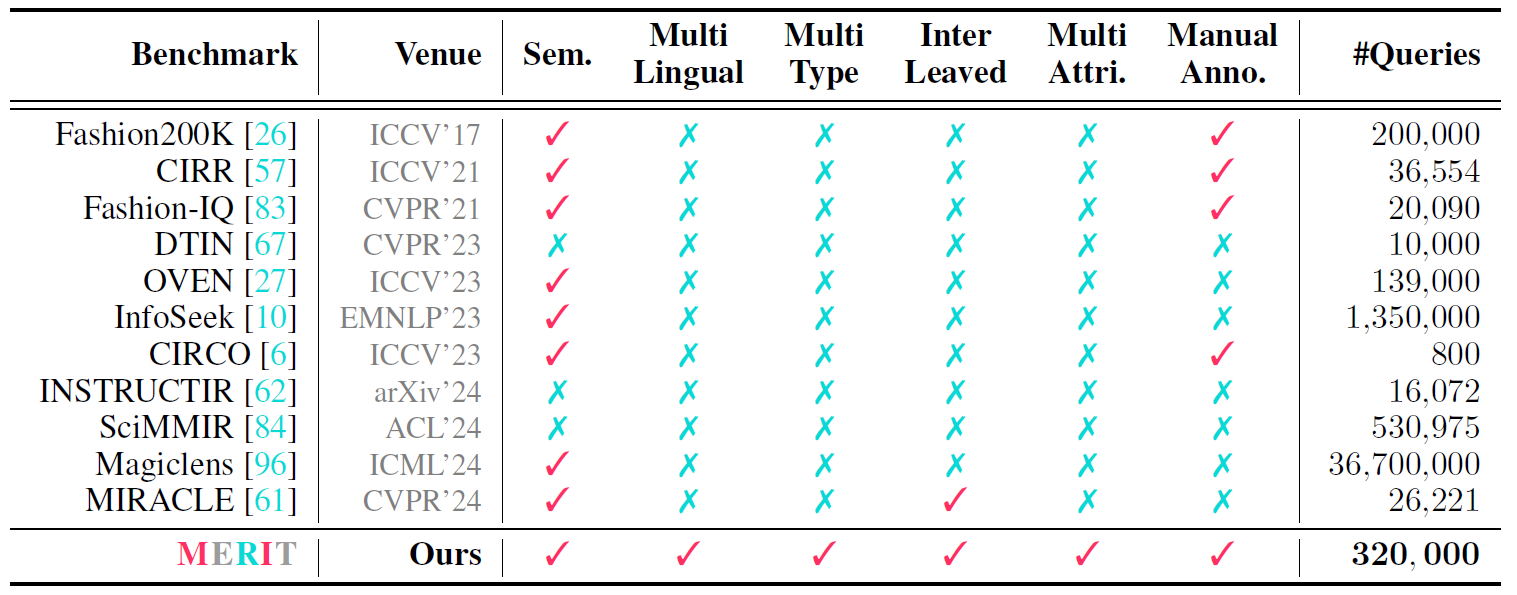
Summary of multi-modal query retrieval datasets. We compare existing works from aspects including: 1semantics, 2multilingual data, 3multiple types, 4interleaved queries, 5multi-attributes queries, and 6whether manual annotations and filtering are applied.
Pipeline
Our data collection ensured quality through manual filtering by multilingual annotators and automated filtering. The process included four steps:
1) Product Selection: We chose popular products from 6 Southeast Asian countries in 5 languages, considering both diversity and quality metrics.
2) Product Annotation: We developed detailed product attributes through open annotation and statistical analysis to address the gap between limited operational attributes and search system needs.
3) Query Creation: Using three sampling methods (uniform, attribute-based, and similarity-focused), we built diverse retrieval pairs while supporting expansion to new product categories.
4) Quality Control: A two-stage filtering process combined automated checks with expert manual review to ensure high dataset quality.
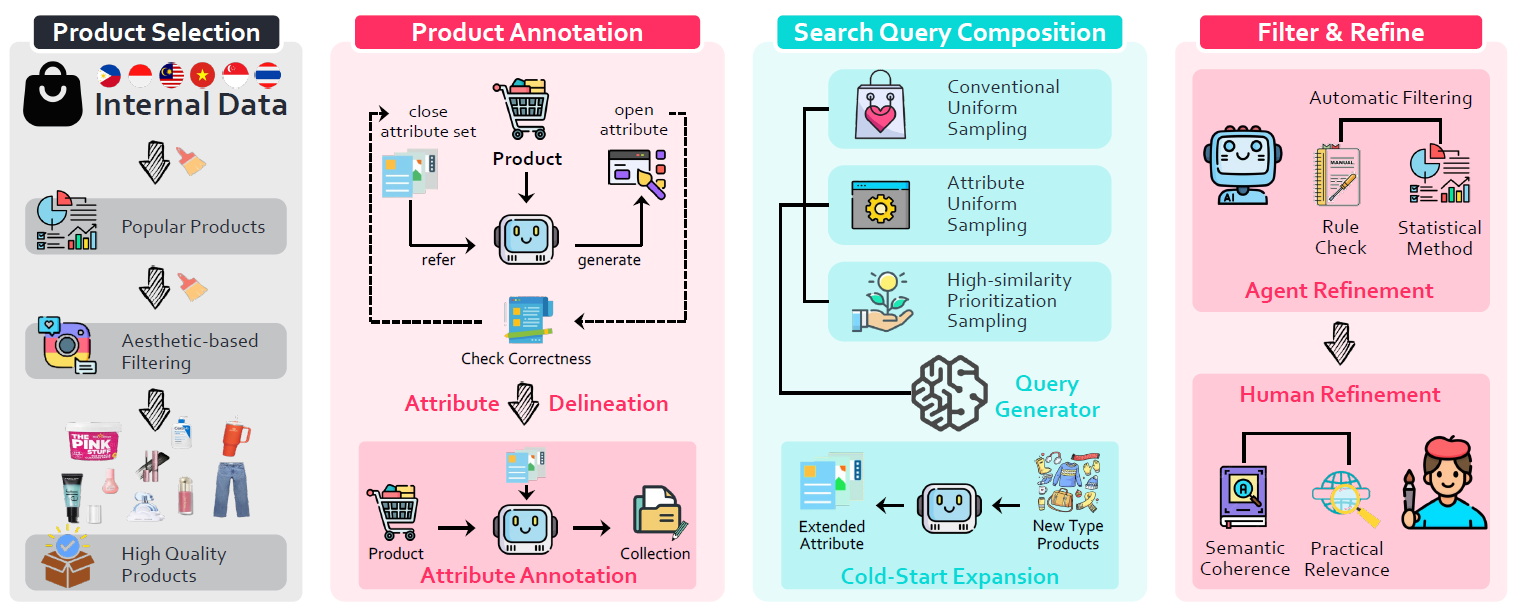
The data annotation pipeline for .
We ensure data diversity and quality through open-set deduplication and
multi-round filtering procedures
in 4 steps.
We first select high-quality products and annotate their attributes,
then combine them into query pairs before performing data cleaning to produce .
Overview
In practice, product retrieval tasks frequently encompass multiple simultaneous conditions (e.g., specific patterns, precise colors, and particular styles), with many attributes necessitating visual representation through images.
However, existing semantic retrieval datasets are limited to single languages, single images, or singular retrieval conditions, often failing to fully exploit the expressive capacity of visual information—a limitation evidenced by maintained performance when images are replaced with textual captions.
To bridge this gap, we present , which encompasses $135,000$ products, resulting in $320,000$ retrieval pairs across $5$ languages (English, Malay, Indonesian, Vietnamese, Thai), encompassing $7$ distinct product retrieval scenarios. Our dataset constitutes a structured query dataset, where each fundamental unit is a product comprising an image and its corresponding title generated by GPT-4o.
Each search query contains at least one positive sample. For convenience, the dataset is partitioned into training and test sets, containing $310,000$ and $10,000$ entries respectively.
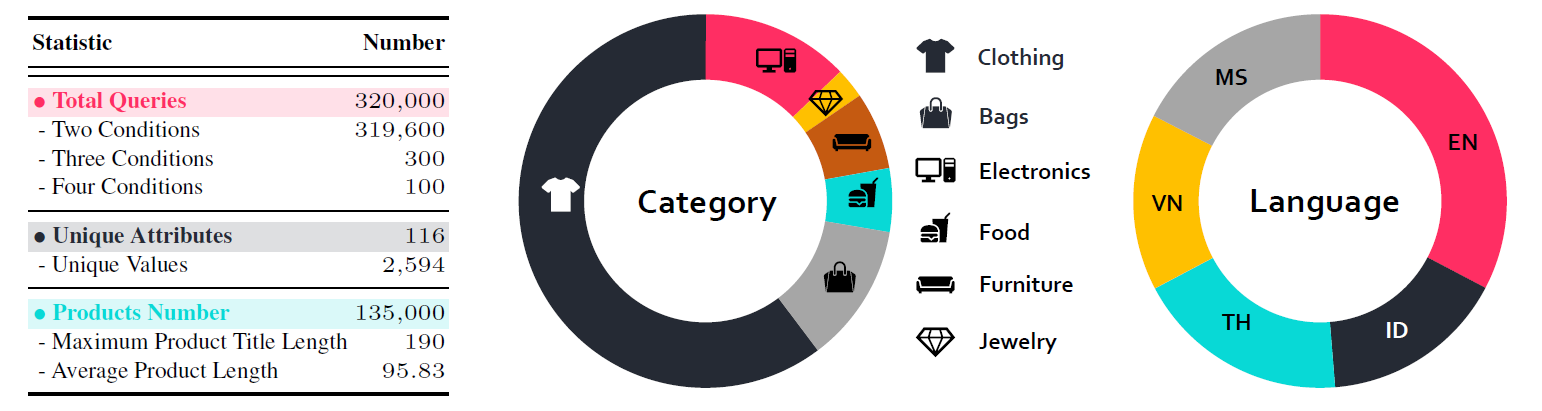
(a) Dataset Statistics; (b) Summary of product categories and language distributions.
Case

A query case in .

A query case in .

A query case in .

A query case in .

A query case in .

A query case in .

A query case in .

A query case in .

A query case in .

A query case in .

A query case in .

A query case in .

A query case in .

A query case in .

A query case in .
How Far to ?
Main Results
To evaluate the effectiveness of existing retrieval models in addressing the interleaved multi-condition semantic retrieval task, we conduct experiments on $9$ state-of-the-art retrieval models. The principal results are presented in our main results table.
is divided into training and test sets, consisting of $310,000$ and $10,000$ queries respectively.
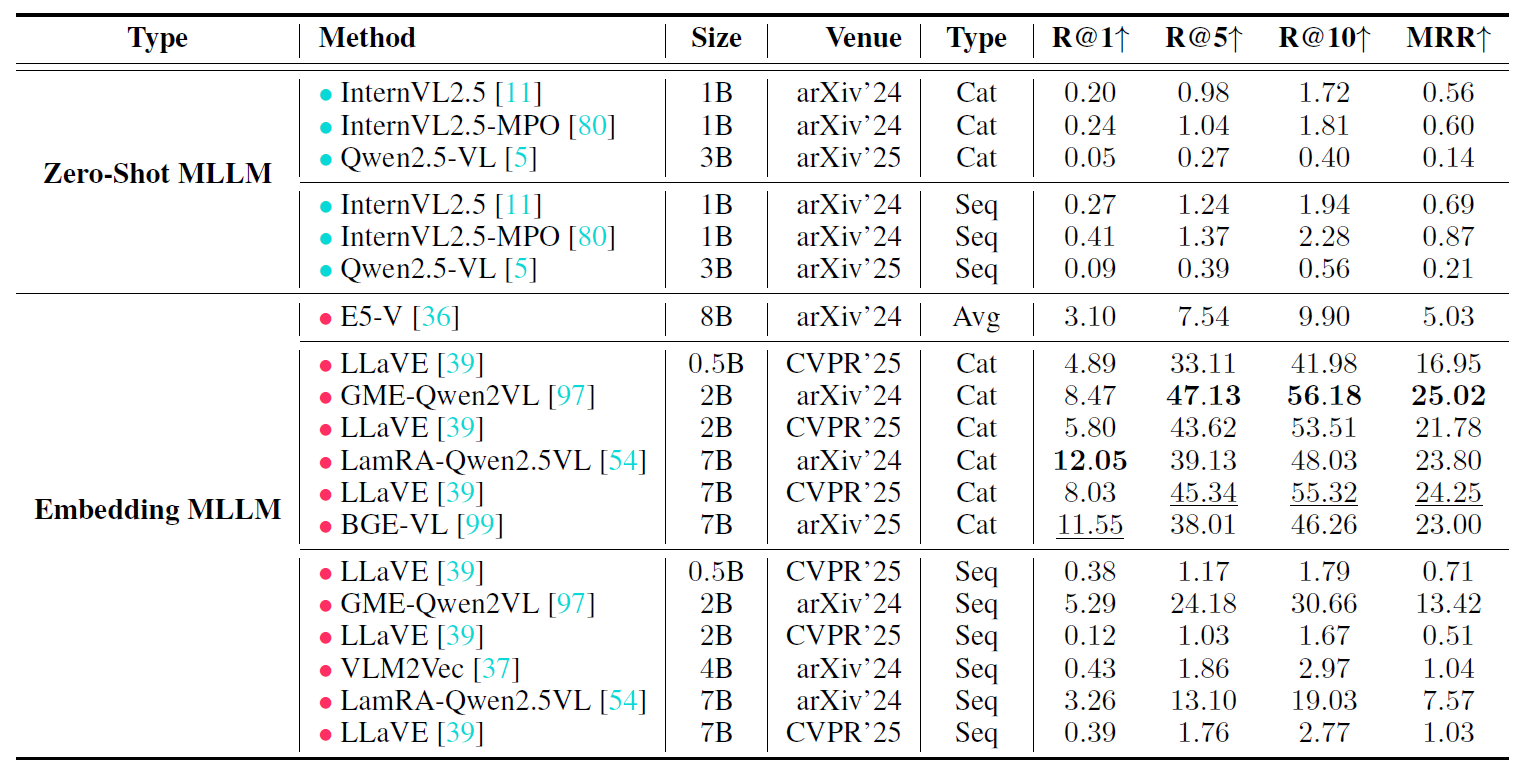
Comparative study of retrieval performance on
.
"Seq", "Cat", and "Avg" denote sequential multi-image input,
concatenated images as a single image input, and averaged embeddings, respectively.
Main Results. Existing retrieval methods struggle to address interleaved multi-condition semantic tasks, with even the best Recall@1 being only $12.05\%$. Additionally, we identify several key insights:
Visual Conditioning Necessity. To verify the necessity of visual information, we conducted experiments using BGE-VL on CIRR, FashionIQ, and our dataset. When replacing images with their corresponding captions for retrieval, the performance on FashionIQ and CIRR does not significantly deteriorate. In contrast, we exhibit substantial performance degradation when either replacing images with their corresponding captions or removing product titles, with image removal resulting in a particularly severe decline of $73.9\%$. This demonstrates the effectiveness of our dataset, indicating that both images and product titles are indispensable components.
Interleaving Support. Concatenating multiple images into a single image significantly outperforms sequential input, with concatenation achieving a $119.7\%$ improvement in R@5 over its sequential version. This occurs despite the fact that pre-trained MLLMs support interleaved image inputs. After training, sequence input performance improved by $14.3\%$, further validating our hypothesis. This underscores the significance of our dataset as the first interleaved semantic retrieval dataset.
Out-of-Distribution Scenarios. We evaluated Qwen2.5-VL on three types of OOD scenarios (Class OOD, Language OOD, and Attribute OOD). Specifically, performance in the Language OOD scenario shows a notable gap compared to full training; however, it still demonstrates substantial improvement over zero-shot performance. In both Class and Attribute OOD scenarios, the performance gap between OOD and full training is relatively small, reflecting the diversity of our dataset.
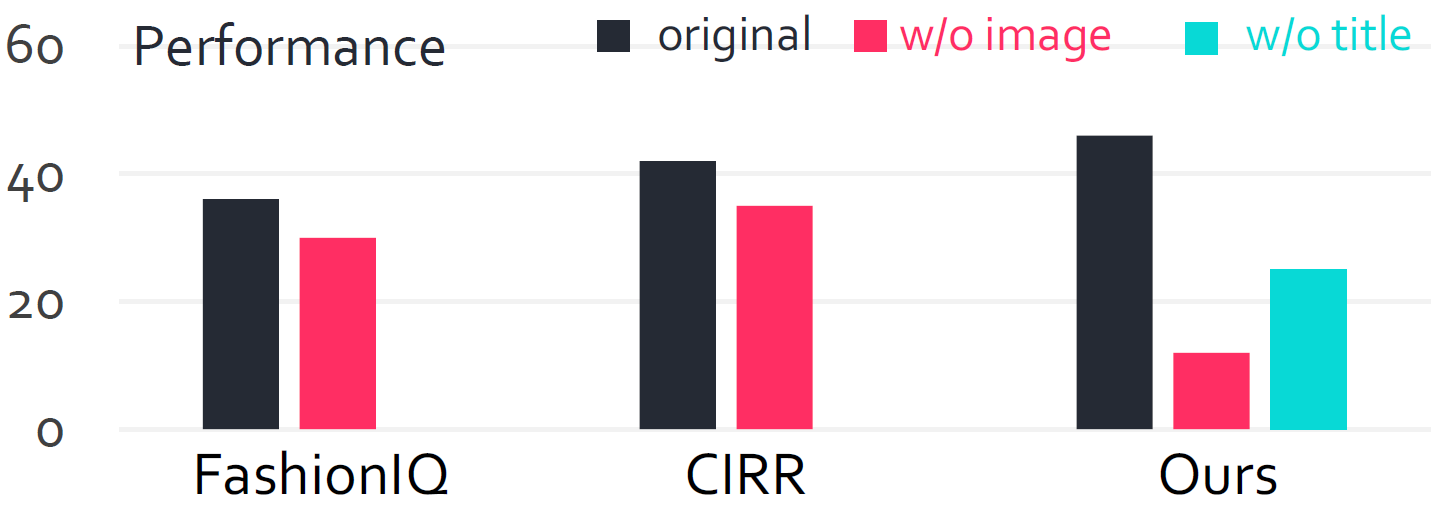
Visual Conditioning Necessity Test Results.
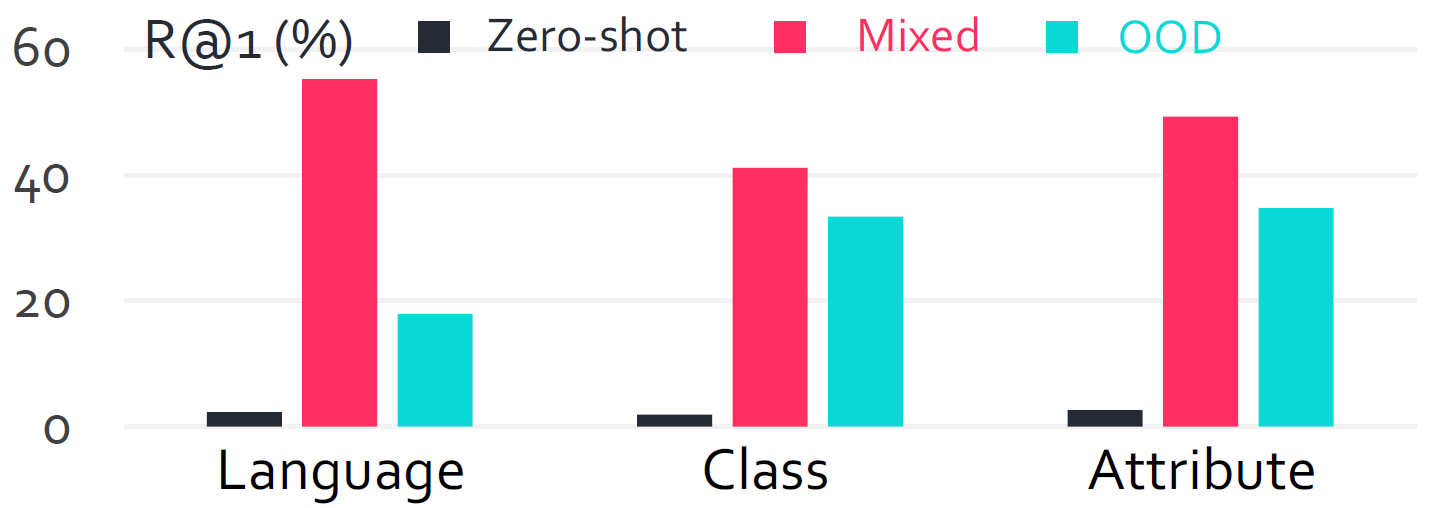
Out-of-Distribution Scenarios Results.
Error Analysis
We examined why retrieval models perform poorly. First, we checked if performance varied by language, but found little difference - English showed no advantage despite being most common in training data.
We analyzed 500 queries using two trained models (Qwen2.5-VL and InternVL 2.5). Experts categorized errors into five types. Most errors involved attributes and visual understanding. Models focus too much on overall meaning and miss specific details, likely because they're trained mainly for retrieval. Current single-image datasets also limit models from using their full ability to understand multiple images, leading to mistakes in identifying details like patterns.
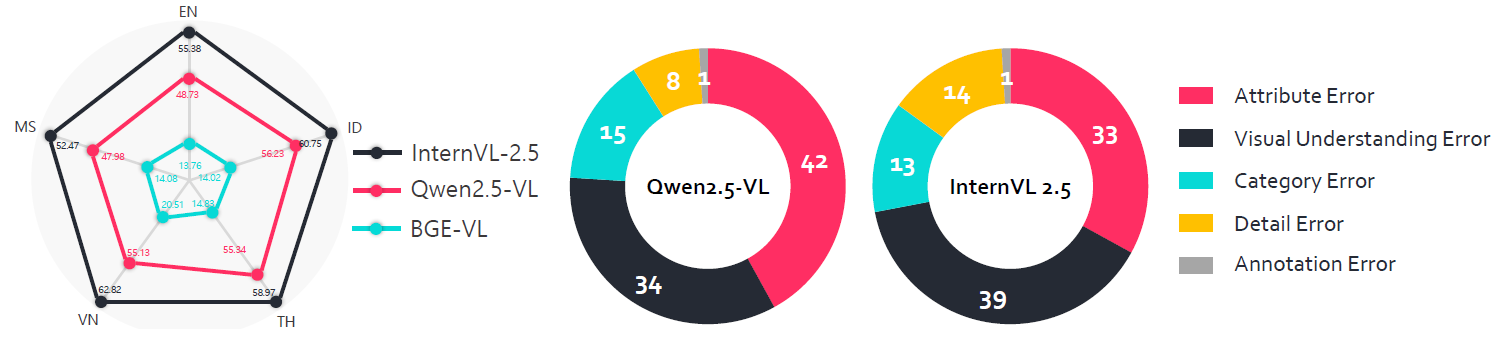
(a) Different Language's Performance on (R@1).
(b) Distribution of Error Types.
Coral
Recognizing neglecting specific conditional elements in queries as a primary source of error,
we introduce Coral to enhance MLLM-based retriever
performance in addressing interleaved multi-condition semantic retrieval
tasks through the integration of visual reconstruction
during the fine-tuning process of the MLLM-to-retrieval model adaptation.
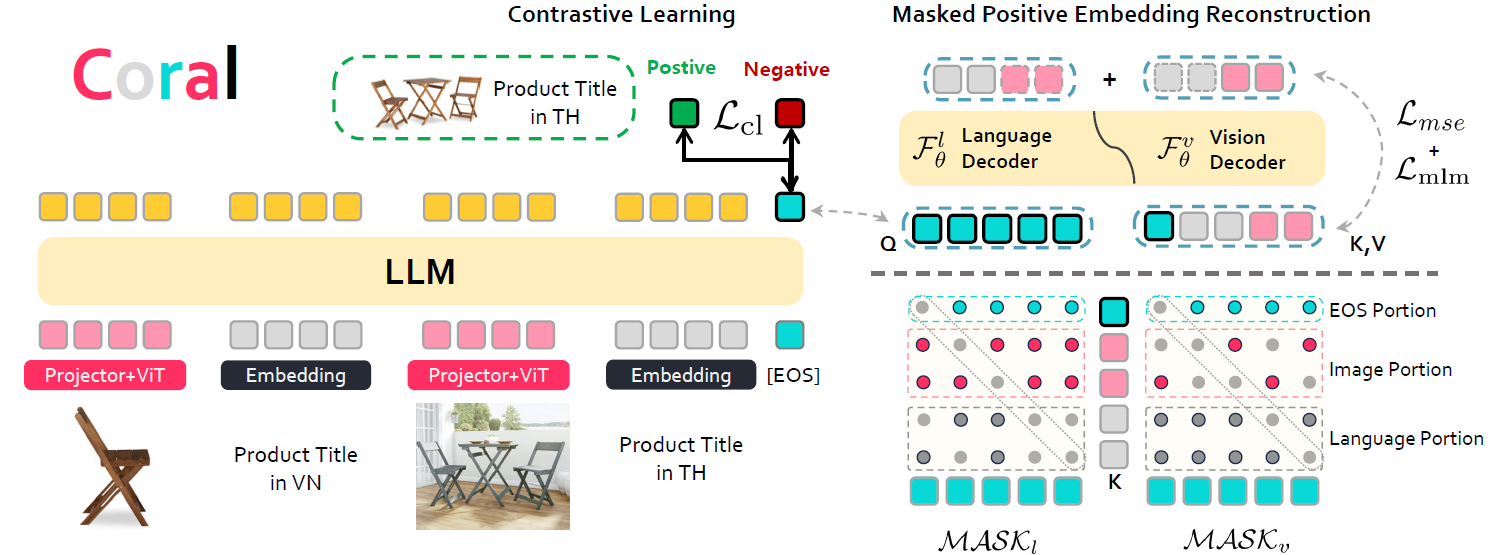
Overview for Coral.
The loss function of Coral consists of three components:
Contrastive Learning Loss $\mathcal{L}_\mathrm{cl}$,
Vision Reconstruction Loss $\mathcal{L}_\mathrm{mse}$, and Masked Language Modeling Loss $\mathcal{L}_\mathrm{mlm}$. During training,
we reconstruct both the query and its corresponding positive sample.
Results lead to the following conclusions:
(i) Embedding reconstruction contributes significantly to retrieval performance. Both partial feature reconstruction enhance model performance, with multimodal reconstruction yielding a 45.9% improvement compared to contrastive learning alone.
(ii) Multi-modal reconstruction outperforms partial reconstruction. Comparing results reveal superior performance when reconstructing both modalities simultaneously.
(iii) Sequential input surpasses image concatenation. We observe that sequential inputs achieve higher performance. We hypothesize that sequential representation preserves more information than image concatenation.
(iv) Full parameter fine-tuning yields optimal results. Due to the substantial divergence between retrieval tasks and pre-training objectives, full parameter fine-tuning generally produces better outcomes.
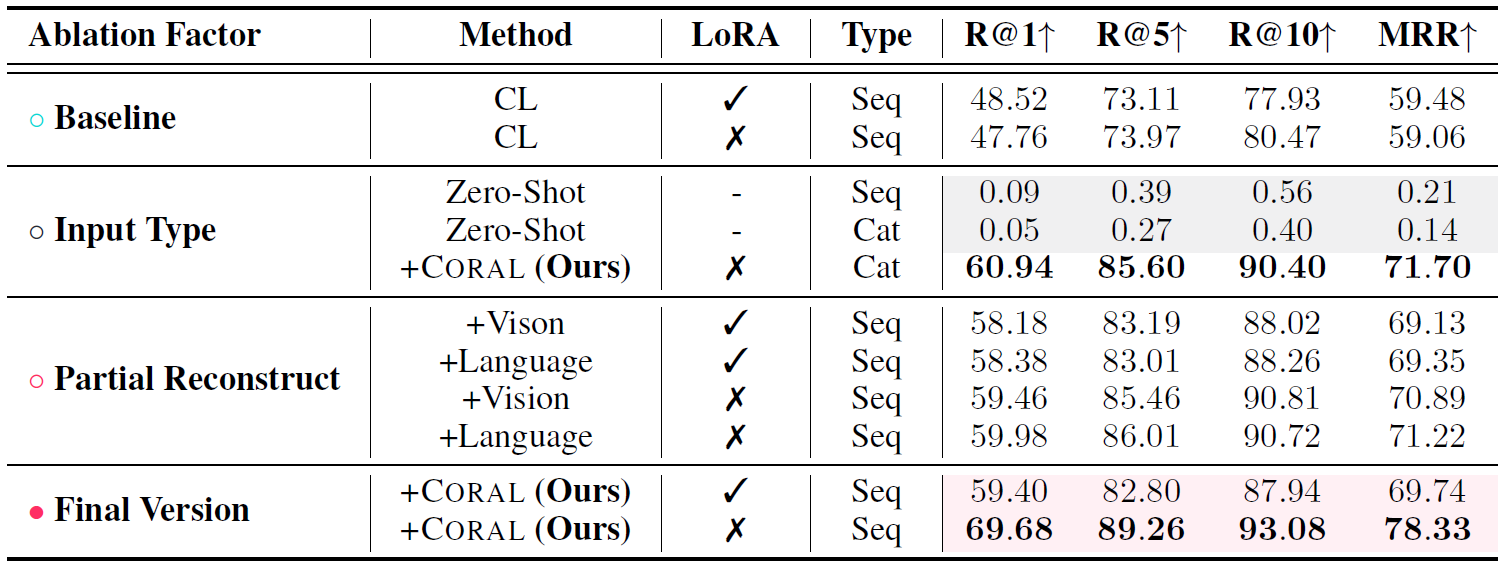
Ablation results of existing methods and
Coral
on using Qwen2.5-VL.
Results on $8$ Retrieval Tasks.
To further validate the efficacy of Coral,
we conducted evaluations on $8$ retrieval benchmarks.
Comparative analyses between our approach and other
foundational models demonstrate that our method achieves consistent improvements across these
eight retrieval tasks, with particularly notable performance on VisDial,
where our approach exhibits a $181\%$ enhancement over the baseline.
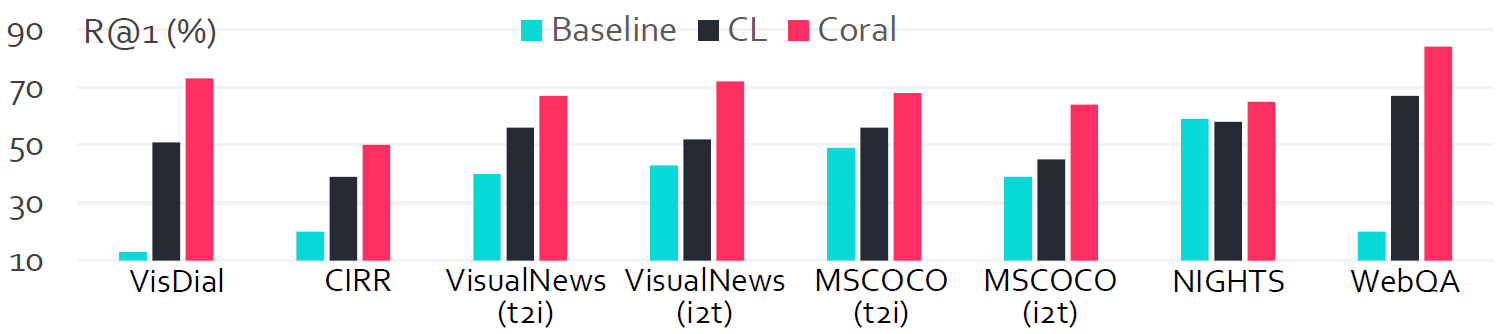
Comparisons of our method with other methods on eight established retrieval tasks.
We take zero-shot Qwen2-VL as our baseline. CL denotes contrast learning.
BibTeX
@article{chow2025merit,
title={MERIT: Multilingual Semantic Retrieval with Interleaved Multi-Condition Query},
author={Chow, Wei and Gao, Yuan and Li, Linfeng and Wang, Xian and Xu, Qi and Song, Hang and Kong, Lingdong and Zhou, Ran and Zeng, Yi and Cai, Yidong and others},
journal={arXiv preprint arXiv:2506.03144},
year={2025}
}